Building gamebiz.news
Intro
I assure you, work on Magivoid is going great with a new devlog coming online very soon! However, as promised in the previous post where I introduced gamebiz.news, here’s some info on the details of how it was built.
This endeavor has been a slight distraction from making games, but coding is coding and it was great fun building this little web app. I learned all kinds of new web and backend technologies. Who knows, Magivoid or some other game I work on may need a backend at some point and I should be able to build that after this exercise. But enough jibber-jabber, let’s get into the weeds.
Overview
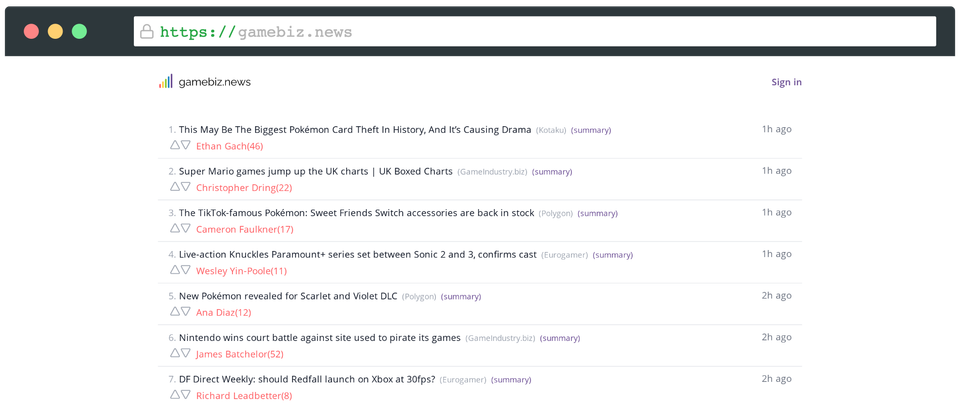
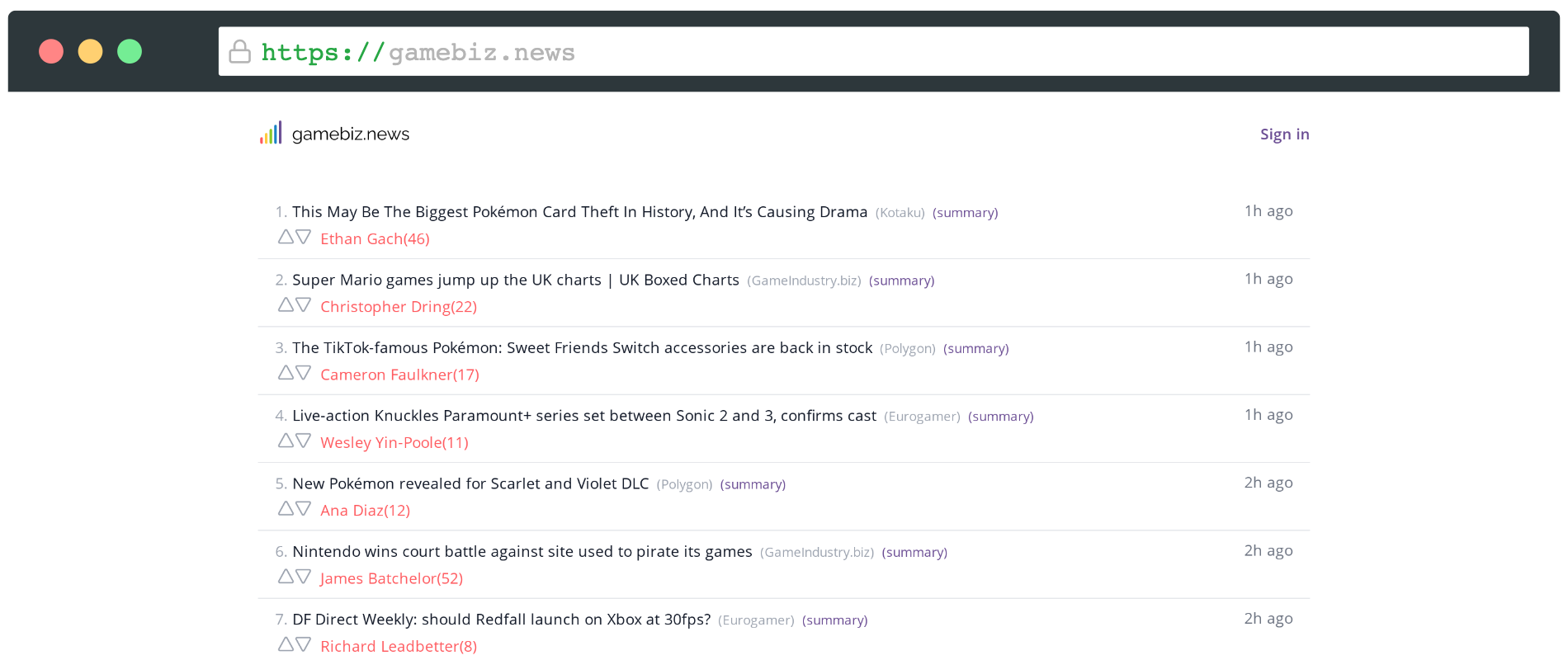
I’m going to assume you haven’t seen gamebiz.news and start with a bit of a description. The app collects news articles from a handful of gaming news websites that I frequent and lists them all in one place. The primary goal was to make it quick and easy to get an idea of what’s new in the gaming world. I’ve had some requests to extend the site with additional sources but I found most of them don’t offer anything unique in addition to the current coverage. If you do think something is missing though, please do get in touch!

Surprisingly, building the basic functionality was relatively fast and easy to do. I kept pushing and implemented some additional features for fun. I added support for up/down voting articles where the score counts towards the author of the article rather than the post itself. The idea is, if the site gets any traction and more people use it, maybe there’s an “author quality” type of metric that comes out of this system.
For the voting to work well, I needed a way to control who can vote and when. This led me to add an authentication and account system. You don’t need to create an account to read the news on the site, but you do need to sign up if you want to vote. This needs to be the case to ensure people don’t abuse the voting system. Or rather, you can’t abuse it easily, I hope. Please don’t try too hard to hack it, I’m sure there’s a way.
Additionally, I planned on adding a commenting system for people to start discussions centered around each post. This has no value in the beginning while few people use the site, so I decided to postpone this until there’s more traffic. I’m looking forward to implementing this system though, and I hope I get a chance to do it soon.
Frontend
The frontend of the app, the website itself, is built using Nuxt3. Making the transition from gamedev to webdev has been interesting, to put it lightly. Everything is open source and there’s a bajillion frameworks, which is more or less the opposite of what you’ll find in gamedev where everything is kept secret and your only tool is the engine you commit to using.
Nuxt is a framework on top of the different framework, Vue.js, which for some reason I gravitated towards and have enjoyed using. I briefly tried React, arguably the industry standard, but it never really clicked for me like Vue did. In addition to wrapping all of Vue, Nuxt also handles a lot of boilerplate javascript setup for you and makes it easy to build web apps without needing to worry too much about the internals. In many ways it’s similar to using a game engine.
My favorite thing about Nuxt is how easy it is to create server-side rendered web apps where code runs on the server (as opposed to in the browser). You write all code in the same place and it’s easy to specify what runs on the client and server as needed. The caveat is you do need a server to host your backend if you go this route as it’s not a static website anymore, but nowadays there are many simple options for hosting dynamic sites and this isn’t really a problem. Server-side rendering can be a great benefit when your site has a lot of text. Search engine crawlers get all that content for their indexing, making your site more visible to additional keywords. It usually also means your site loads faster since the final web page is delivered and no (or little) javascript has to run client-side to render the page.
For the visuals I really like Tailwind and how easy it is to make nice looking UIs with it. Some people dislike the inline way you have to set up all your classes, but I’ve found this to be a positive. I’ve always disliked having CSS data in a different location from the HTML element.

Anyway, I’m not really a webdev and you may want to consider other resources for more legit suggestions if you want to get ideas about what to use yourself. Tailwind has worked great for me and with minimal, if not zero, skills in user interface design I managed to create something that’s not horrible on the eyes.
Authentication
As mentioned previously, to keep the article voting fair and controlled I needed a way to limit who gets to vote and how. I wasn’t about to write a new authentication system from scratch, which sounds like a complicated system to implement well, especially with all the great solutions out there already.

I decided to use Supabase for this. In fact, I’m using Supabase for both authentication and the backend database. The database is just a managed Postgres instance with great RLS support connected to the authentication system. This lets me create user-private data in the future, if needed. At the moment RLS is only used to make sure authenticated users are the only ones that can vote on articles and of course limit who can add new articles to a service account used by the backend script.
Backend script
So far we have a website and a database to store all the data. The only problem is, the website is empty because the database is empty. We need a way to populate our database with the articles from various sources.
I already had a list of a handful of gaming news sites that I like. The next step was to somehow automate the retrieval of data from these sites to populate the database. I decided to use Go for this step. I can’t remember if there was a specific reason for this choice. I just really like Go for quick hacking projects and use any excuse I can to make use of this language, so here we are.

I wrote a simple console app that reads an RSS feed, iterates over all items in the feed, and extracts the relevant data. That relevant data in this case is just the URL of the article, the author, and its publication date. Once the data is parsed from the RSS feed, it adds an entry to our database for each article.
The database also holds a table with all known authors across all news sites. When the script parses the RSS feeds, it looks at the author of each item and makes sure we have an entry for them in our database. If we don’t, a new author is added so we have something to connect each article to.
After processing all the RSS feeds, the script does a pass over all authors in the database to calculate their up-to-date score. The score for each author is a combination of the number of articles written by them, the sum of all upvotes, and the sum of all downvotes. This total score is then written back to the database, ready for our frontend to display as needed.
This script runs as a cron job every four hours and continuously updates our database with new data as new articles are being posted across the internet.
AI summaries
I realized that often I tend not to read full articles. Occasionally I read the whole thing, but in most cases I either just skim an article or, worse, read only the headline. Once I had my backend script parsing the RSS feeds of all my favorite sites, I also learned just how many articles are actually published every day. You don’t get a clear impression of this by randomly visiting websites, but when you get every new post printed to a log every four hours you see exactly what the volume is. There is no way I would have time to read all these articles every day.
I didn’t plan on solving this in any way, but a friend of mine accidentally gave me an idea. He was at the time working on an app of his own using generative AI. While both of us were hacking on our projects we kept discussing random ideas. All that talk about AI spawned the suggestion of auto-creating summaries. After all, AI is meant to be pretty good at this stuff.
A short google search, a few bounces of the idea between my friend and I, and a few hours later I had AI summaries working and live on the site. It really took only a few hours to go from idea to having it run and work well, and I will tell you what the secret is: 🤗
Hugging Face is an amazing AI community where you can find all kinds of information and ready to use solutions. For my site I ended up using a deployment of the facebook/bart-large-cnn model.

The implementation of AI summaries consisted of some minor frontend UI tweaks to pull the summary text from the database and display it as needed, and a small addition to the backend script. Unfortunately, the RSS feeds for the sites I gather articles from don’t contain the entire article. Some of them have a short summary, but getting an AI to summarize a summary didn’t produce meaningful results. Displaying the summary provided in the RSS feed was also out of the question as some of them had ads and other random links in them that I didn’t want on my site. I needed a different solution.
The solution ended up being an HTML scraper. We already have a URL for each article we process. It was a small step from there to visit that URL, find where the meaty text of the article was, and extract the entire thing into a string. This then gets passed to our AI model and back comes a sweet summary that was surprisingly well phrased in most, if not all, cases. The summary then gets added to the database along with the other article specific data for the web frontend to use.
Deployment
To get the whole party deployed required a few moving parts but it wasn’t as complicated as I initially expected. The web frontend and backend is deployed to Vercel. Nuxt is already set up to very easily deploy to Vercel so this just worked with minimal setup from my end. Each time I commit changes to my main branch in Github, it auto deploys to Vercel and changes go live.
Gamedevs, imagine every Perforce commit being cooked into a patch that gets auto deployed to your players. Wouldn’t that be quite the future?
The backend script that gathers article data runs as a cron job on a $5 VPS from Linode. It’s a very low-cost script that doesn’t require much resources to run. In fact, this is the same VPS that runs my Perforce server for Magivoid.
For the AI summaries, the model used is running on Hugging Face. There are various options for deploying workloads there, it’s really a great platform. Again, this is also a low-cost requirement as we really just need at most ~30 articles summarized every four hours. If this ever scales to higher numbers we may need more oomph here, but I haven’t noticed any issues so far.
Discord bot
Overall this project has relatively few moving parts with not much that can go wrong. Still, we’re dealing with internet connections, multiple websites, APIs, and a bit of automation that would be nice to keep track of. I don’t really want to SSH into the VPS to check logs regularly either, so I came up with this odd gimmick for keeping track of when things go wrong. I know there are various professional solutions out there, but they are all overkill for my needs. All I need, apparently, is a Discord bot that posts warnings and errors to a channel on my server.
I’ve had the Discord bot hooked up to the website backend at some point, but decided this wasn’t worth the spam it generated when the site got a bit of traffic. At the moment, the bot only runs within the backend script that gathers the article data.
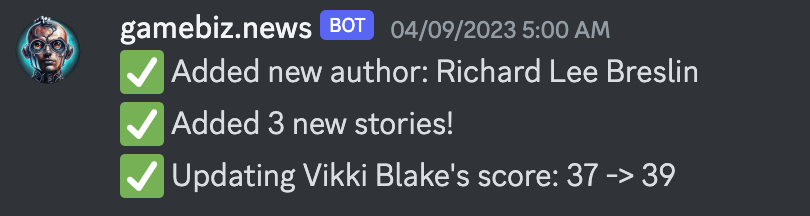
Every four hours I get posts to a private Discord channel telling me how many new articles have been processed and added to the database, how many new authors have been added, what each author’s updated score is, and if anything went wrong with the data gathering. It’s a nice, passive way to keep track of any issues that might potentially arise.
Summary
This web app has been made possible by Nuxt handling the web front/backend, Tailwind to make it pretty and Vercel to host it, Go to implement the script to scrape article data, Supabase to store everything in a managed Postgres instance and provide an authentication system, Linode for a stable and cheap VPS, and last but certainly not least, Hugging Face with the terrific AI solutions.
One unexpected thing I realized once the site went live was I now read more news articles than I did in the past. The short summaries help me identify what I really care about and having links to multiple sources in the same place makes it faster to jump to the articles I find interesting.
I hope this has been somewhat informational or at least interesting to read. If you have any questions, feedback, or think I may be able to help in any way, don’t hesitate to get in touch!